Launch spark shell on multiple executors
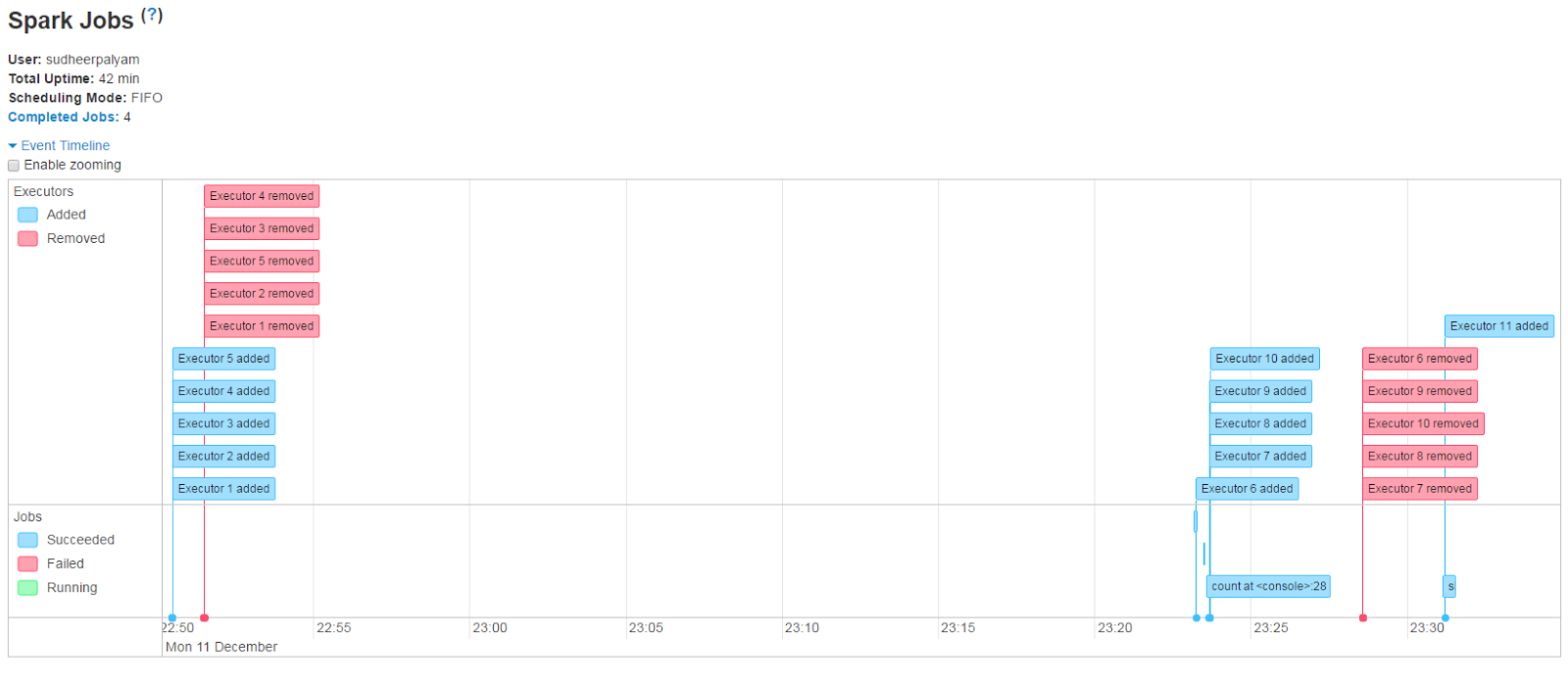
Example: spark-shell --deploy-mode cluster --master yarn --executor-cores 4 --num-executors 6 --executor-memory 12g Like how we tune spark-submit parameters, same tuning parameters are applicable for spark-shell as-well. Except that deploy-mode can not be 'cluster', of-course right. Also make sure spark.dynamicAllocation.enabled is set to true. With these settings, you can see that Yarn Executors are allocated on demand and removed when no more required.
